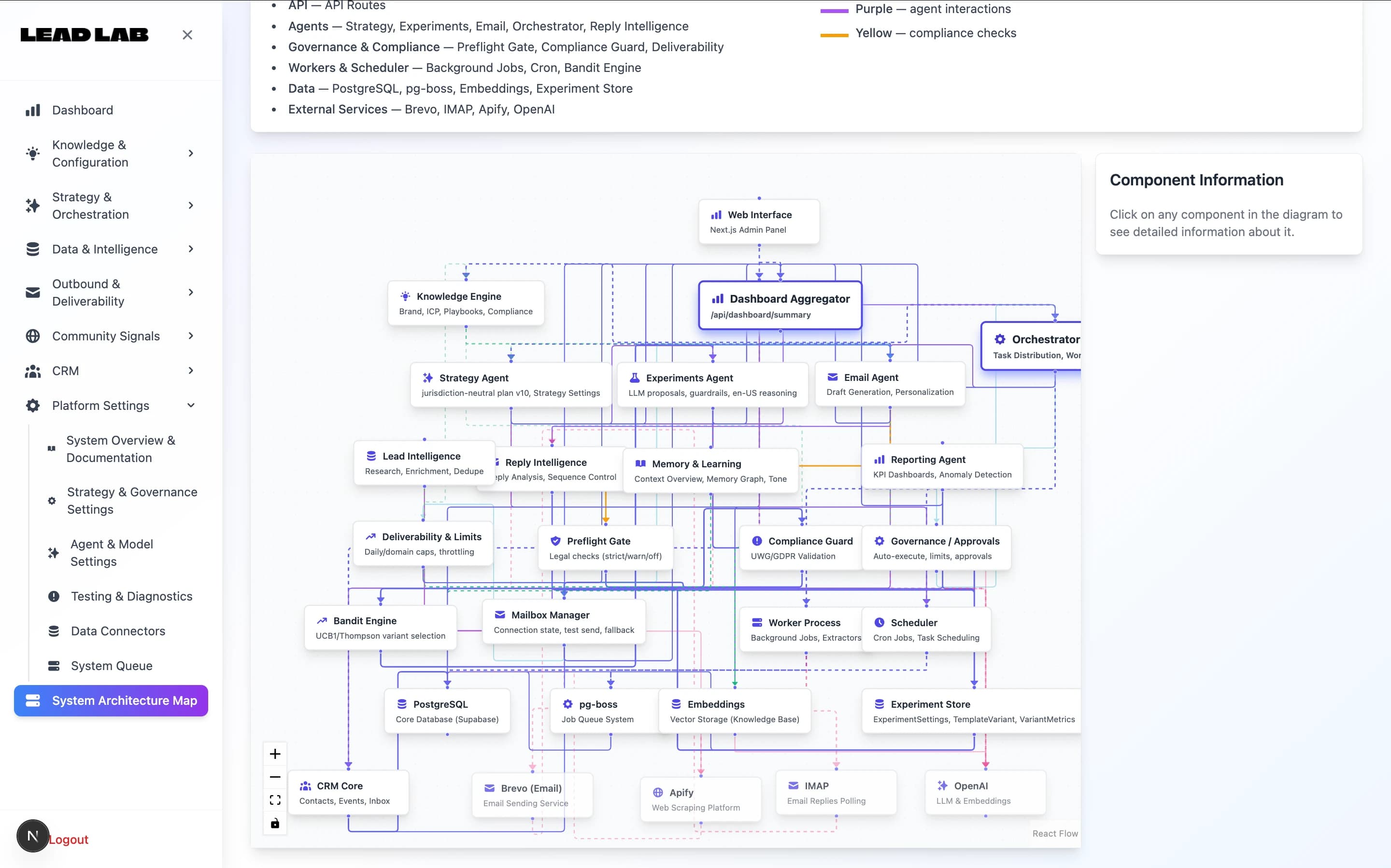
Enterprise prospects ask questions the MVP wasn't built to answer
SSO, auditability, access control, data flows — requirements that were never part of the original build start appearing in customer and security conversations.
Four situations we see repeatedly once a B2B SaaS product moves past validation.
SSO, auditability, access control, data flows — requirements that were never part of the original build start appearing in customer and security conversations.
How accounts, organisations and tenants relate was decided early and quickly. Changing it now touches more of the system than it should.
Each new plan, exception and customer arrangement adds another branch to billing and subscription handling, and the logic gets harder to reason about.
Shipping a new feature now often means untangling something underneath it before the actual work can begin.
The parts of a B2B SaaS product that most often need structural attention after MVP.
Representative technologies for B2B SaaS product work — not a fixed prescription.
Stack choices are defined per product, existing team capability and customer requirements.